’Single-sourcing’ is a method of content management common in technical editing, and something I have used in various forms for years to manage my thoughts and notes, and (ultimately) any presentations or publications that come from them. The aspiration of single-sourcing is to have one document source which can be transformed (without further editing) into multiple output formats.

In my own case, I want to be sure to pick up any errors in, for example, a slide that the audience notice, or a handout that doesn’t make sense outside the presentation, or in my speaker notes. In theory, the error needs only be corrected in one source and the multiple outputs will all be corrected.
I also want to be sure to collect all my sources (web links, news stories, images and stray thoughts) as comments and margin notes in the same document, without necessarily displaying them.
Technology and reading
There is a lot of debate about how, or even if, technology changes reading and subsequent thinking. There are plenty of downsides to technology and plenty of upsides — I end up with the same document in a bookshelf, on my eBook reader and on my laptop, because each have different functions for me. Single-sourcing can make me think about how much (or how little, usually) an image would mean without explanation, or when a quotation needs extensive notes and referencing, or how spoken words, a handout and a book would treat the same subject in entirely different ways.
The greatest function of all is accessibility — who, for instance would have access to a physical copy of the speeches of 19th century Dublin judge, Sir John Philpot Curran without electronic scanning? Yet the words “the price of freedom is eternal vigilance” (so often misused to justify oppression), can be seen in context at Archive.org: “THE aldermen, however, soon became jealous of this participation, encroached by degrees upon the commons, and at length succeeded in engrossing to themselves the double privilege of eligibility and of election; … The condition upon which God hath given liberty to man is eternal vigilance; which condition if he break, servitude is at once the consequence of his crime, and the punishment of his guilt.” https://archive.org/stream/speechesrightho00currgoog#page/n37/mode/2up. Likewise, an absolute treasure trove of world history has been made freely available in the 1987 “History of Cartography” from the University of Chicago http://www.press.uchicago.edu/books/HOC/index.html. Nothing compares to seeing The Last Judgement by Hieronymous Bosch in the Alta Pinekothek in Munich, but printed works and Wikipedia let us visit a high-quality image. Accessibility is being encroached upon now by corporate powers who are glad to share less than they learn, whilst restricting access to empowering knowledge. University fees are punitive, ’books’ have subscription with digitally-controlled access and newspaper news has paywalls. The people who would most benefit from knowledge are the people most disadvantaged by commercial pressures, despite the promise of equal access to digital content.
Even the school bag, which could be lightened by digital content on a single electronic device, has become a burden with updates, subscriptions, logins, data theft and the incredible pricing of digital texts that were cheaper and more durable on paper. The Open-source Education Resources movement tries to provide digital copies of textbooks with no restrictions — you can copy them, give them to friends, listen to them through text-to-speech, feel them on a Braille reader, print them, even modify them for other uses. Some examples are http://www.ck12.org/, the State of California http://www.opensourcetext.org/ and more listed at http://classroom-aid.com/open-educational-resources/curriculum/. You can, obviously, contribute to these texts and improve them. Some US states pay their teachers to contribute to textbooks.
Single sourcing and Truth
I don’t believe that anything I write is ’The Truth’. I never intentionally write false statements, even playing Devil’s Advocate, but I do believe that what I write is true, to the best of my knowledge, and possibly one amongst many truths. A lot of what I write is similar to the concept of Best Available Technology Not Entailing Excessive Cost (BATNEEC), which is to say I write the best I can within the available time and resources. I don’t expect it to be perfect or entirely correct, but someone out there can correct my errors with far less effort than I can.
Single sourcing is a great way to keep all the axioms, newspaper remarks and personal beliefs together as an ever-changing repository of Best Available Truth, with a visible expression of my current opinion in the output documents. I can see and check all my resources whenever I update a presentation, including new sources of knowledge and deleting old sources. I rarely delete — almost every document I have ever read, every image I have looked at and every piece of music I have listened to are accessible as a copy or a link.
One software package I have used a lot in recent years is a whole-disk indexer. The one I use is called Recoll, but there are plenty of alternatives. A quick search will find every document, tagged image or tagged sound file that matches words or phrases, with the choice of exact spelling, sounding alike or having the same stem. It almost always locates half-remembered quotations and finds links between texts that I had never noticed (e.g. novels with a character with the same name).
Choosing the single source format and medium
Many software packages provide some element of single sourcing — every wordprocessor will do automatic content lists and index lists, presenting the text within particular styles in a different format. Wordprocessors can also use a master document to build output from multiple, smaller input documents. Choosing the right package is important, and depends on individual needs.
I ended up with WikiCreole as my choice, although Markdown or Wiki markup would work just as well. The essential feature for me is that the source document is plain text, without any styles or hidden codes of any kind. The editor is any text editor (e.g. Notepad in Windows, Jota on an Android phone or Gedit in Linux). The markup of the text is written explicitly in the text — e.g. a line that starts with a single ’=’ is a top-level heading, ’==’ is a second-level heading, text inside ’**’ is displayed in bold. There are no hidden fields containing authorship information, editing time or previous versions (as in wordprocessors, which have embarrassed some public figures).
Markup in text also tells the reader (or tells code) what the purpose of the text item is. There should only be one top-level heading, and it is treated as a title. Any second level headings are treated as chapters, and can be made to start on a new page in a book or slide show, or after a horizontal rule in speaker notes. Picking out all the headings is an instant table of contents, or picking out images, internal links and web links. It is easy to check that images and web links have a meaningful description (the ALT tag), including descriptions that stand in place of the image. I treat every line starting with a ’#’ as a comment, to store ephemera, random jottings and unfinished ideas, which are stripped out of all the output (except, perhaps, a printed copy to work on when revising an old text, where you want to see literally everything).
Your own choice of software may be the office suite you already use, or a content management system (such as WordPress), a wiki format, or a single-source editing package. Your choice might be paper or index cards and a pencil. I like plain text, which I can edit on any device and for which I will probably always have an editor, anywhere.
Output formats
I tend to produce text with sparse formatting and occasional images. My styling is mostly limited to headings, bold, italic and bullet points. The images tend to be either postcard (3:2) landscape or postcard portrait, and rarely require anything more complicated than appearing in the correct sequence. I never use animation, but would happily refer to a video if it conveys the message better than text.
Most of my text is for straightforward linear use as notes, shopping lists, reference material and book paragraphs, which I just want to style and print out. Sometimes I need to produce a set of visual slides for a presentation, with limits on how much text fits on one slide. Every presentation needs a handout with a textual summary of the presentation, including descriptions to replace the images and remind the audience of what was said — they can find the images online or in the references, as long as they are not copright protected. Every presentation also needs detailed speaker notes as a reminder of what to say and the sources supporting any statements. I like to keep all of my thoughts inside the source document as well, but do not want to be distracted by them in the speaker notes.
My output for my own use is in the form of HTML (web language) files, which are easy to read in any wordprocessor or web browser. It reflows nicely to produce different sized text (e.g. if you need larger text to speak from, or smaller text to save paper revising a draft) and images can be resized or opened in a new window. Every link — either local links, or links to internet sites — is live and can be clicked.

The fabulous Beamer LaTeX package is a great method of producing interactive presentations, with automatic slide numbering and content lists. I convert my source document to TeX, including only headings, top-level paragraphs, bullet points and images. Slides do not contain any indented paragraphs, comments and some other content that might be visible in the speaker notes or handout. Beamer (accessed through PDFLaTeX) will automatically generate a title page, sidebars and footer text.
Presentation handouts also omit second-level (indented) paragraphs and comments, but include more text elements than the presentation. Every image (which might take a complete slide) is replaced by alternative text where I can describe the message of the image and (if it is not a copyright image) provide the source.
Disposable documents
It is important to think of the output as an ultimately disposable outcome — there should be no editing, refinement or alteration of these outputs. The only human intervention should be in the single source document, which is where all the value is stored. (If you need to keep dated copies of a document, then Git is a brilliant version-control mechanism – especially if the document is a book or multi-author document made up of parts that change).
Every output document can be recreated with a single command or a single click of the mouse, so energy should be expended on the tools that are part of the processing path or on refining the source. Designing the look of a document or slide is a job that potentially never ends, and is best left to designers. Processing paths that put information into a format that fits the design, and writing the words, should be a separate task.
Writing without design and styling is distraction-free writing. Using a text editor (instead of a word processor) that has no menus beyond loading and saving text is a blessing. So is writing in an environment that has no web browser, no email and no instant-messaging pop-ups. It is easy to switch off the WiFi or install a writing environment that has no distracting software.
Links and pictures
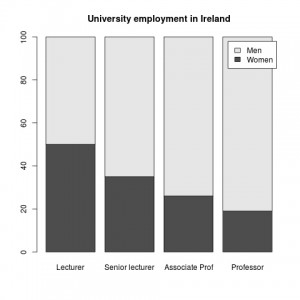
One of the fabulous capabilities of plain text is the ability to store not just the source of an image, but also the method of creating it. For instance, the following line of text is a command to start the R statistical package and generate the barplot above:
# R –no-save –norestore -e ’Women<-c(50,35,26,19); Men<-c(50,65,74,81); Employment<-rbind(Women,Men); png(“Gender.png”); barplot(Employment, main=”University employment in Ireland”, names.arg=c(“Lecturer”,”Senior lecturer”,”Associate Prof”,”Professor”), legend.text=TRUE); dev.off()’
This image shows the number of women at entry to university lecturing (50%) and the attrition through senior lecturer (35%), associate professor (26%) and finally just 19% of professors (with numbers derived from the 2014 HEA report on Gender and Academic Staff). Storing the code to generate the barplot means that I can update the figures with the next report and include the updated plot in the document – the text editor I usually use (Gedit) will run the selected text as a command, from within the text editor.
The diagram of the single-sourcing routes, above, was generated with the code below, using GraphViz, with the command ’dot -Tjpeg SingleSourcing.dot -o SingleSourcing.jpg’:
# digraph SingleSourcing {
rankdir=LR;
node [fontsize=”18″ style=filled]
“Notes (WikiCreole)” [fillcolor=”pink”]
{ “Ideas” “Curriculum” “News” “Journal articles” } -> “Notes (WikiCreole)” -> { “Presentation slides” “Handout (PDF)” “My notes (html)” “Article/book (ePub)” } -> “Reflection and comments” -> “Notes (WikiCreole)”
}
Links to websites can often be complicated and very long, but (as with web pages) can be replaced with meaningful text such as “the Citizen’s Information website” or an abbreviated version, perhaps “search for working with a disability at www.citizensinformation.ie” instead of the full URL http://www.citizensinformation.ie/en/employment/employment_and_disability/working_with_a_disability.html, which is still accessible by hovering over the link in most web browsers. Long URLs don’t format nicely in many formats.
Some neat text-handling tools
The best feature of plain text is that it is accessible — it is easy to search, easy to include in other documents and easy to find software to edit. Plain text can also be manipulated with tools that are rarely as simple in complex text formats. One of these is Grep, a regular expression parser. This returns all the lines that contain a search expression, or just the matching element rather than the complete line. The start of a line is indicated by a ’^’. Some examples are:
A complete outline of a document using ’grep “^=” document.wiki’ (all lines that start with ’=’, i.e. all headings), or even a complete outline of all the documents in one folder using ’grep “^=’ *.wiki’. By naming folders so that they are sorted in the right order (e.g. “Lecture 01”, “Lecture 02” etc), it is possible to produce an outline of all the lectures in a complete course (’grep “^=” Lecture*/*.wiki’).
With a little more effort, it is possible to include the first text item in addition to the headings, so the outline will include the introductory paragraph, creating a summary of the document or collection of documents.
Grep can return just the pattern, rather than the whole line, so a list of all the link URLs can be returned with ’grep -o “\[\[.*\]\]” document.wiki’ or a list of all the images with ‘grep -o “{{.*}}” document.wiki’. It is easy to process this list by piping it through another expression — the first grep returns all the links, and the second excludes all those that have ALT text descriptions, leaving a list of all the links that do not have a description: ’grep -o “\[\[.*\]\]” document.wiki | grep -v “|”’.
It would be easy enough (although I have not done it myself) to use a markup term — even just the emphasis or strong elements — to select text elements to include in an index, and automatically link the index and text locations. I do use anchor elements in headings, which Beamer recognizes as Sections to include in the sidebar table of contents, and which cross-links within the text (so, for instance #Single-sourcing should link to the first section above.
Thoughts, comments and asides
Margin notes and ephemera are really important to me. I never throw anything away, unless I find that re-reading it is distracting, pointless or hurtful (sometimes a reaction to a hurtful news report can be productive, but perhaps keeping the hurtful words is not healthy). I use indented paragraphs and comment lines to store these, although markup within comment lines is not converted to styling — so link URLs don’t work and there are asterisks around strong elements, instead of strong.
In second-level paragraphs, which do not appear in handouts or presentations, I include all the web links and links to local documents that I need to refer to. When I read the speaker notes I can click on links and re-read any source materials, and I can collect lots of links into a document when I start work on a topic. As I visit each link, I can write and revise my own text.
In the comment lines I keep all the random, stray thoughts, the comments from other people, things to check, half-remembered quotes and other unfinished material. Some of this will never be used for anything, but it is still there, just in case. If I revise a book after several years, there might be useful thought processes saved that lead me to believe a particular truth at the time I wrote it — something that, years later, I will struggle to understand why I wrote it a particular way.
Sometimes the comments can allow breathing room for all the stuff that is constrained by space, without growing frustrated at losing it. A one-hour presentation might generate lots of ideas and possible expansions on those ideas that will never fit in the hour, and having a parking zone to put them all lets me continue writing without being limited by a sense of frustration. Sometimes an unformed idea is potentially offensive, and needs care to develop fully, considering the possible effects it might have on a reader. Comments that are withheld from the output text are great for these unfinished elements.
Reflection, feedback and rewriting
In the diagram at the top of this article, all the output paths lead to a potential “Reflection and comments” process in which the words are reconsidered. This might be a formal process of feedback from an audience, editor or invited reader. It might be an informal process of revisiting text and revising, or of rethinking the content in the light of a news story or a novel. Some other tools can be used to systematically explore and reflect on text.
I love wordlists, simply counting the number of times that each word appears in a text and listing the most frequent. These frequent words (after excluding the most common words in the language) are often a summary of the content. They can also flag unintentional use of a term or phrase, such as “person with autism” or “autistic person”, that might reflect the materials used for research. The most common words in the third lecture in one course are disability, people, Social, hair, autism, disabled, disability-studies.leeds.ac.uk, autistic, Model and Alliance — it is a lecture about the Social Model of Disability and autism, with hair-loss as an example of impairment. On checking, I can see that the person-first language actually comes from my sources and illustrative quotations, which I always try to reflect.
Wordlists can be combined to produce new information. For instance a wordlist tool can find all the words used for the first time in lecture 3, that have never appeared before, using ’wordlist Lecture3.wiki -not Lecture1.wiki Lecture2.wiki’: hair, disability-studies.leeds.ac.uk, Alliance, Union, files, UPIAS, image, complaint, 1975, physically and principles. It is time to define the Union of Physically Impaired Against Segregation (UPIAS), the Disability Alliance and the disability archive at Leeds University.
It is also possible to calculate a statistical measure of the relative word frequencies. For instance the following words are far less frequent in Lecture 3 than elsewhere in the course: repetitive, autism, disorders, developmental, child, childhood, Asperger, syndrome, children and disorder.
Word clouds


The same word lists (or even the URL of a blog post, or the full text) can be turned into a word cloud. There is probably good software for this, but I like Wordle and use it for word clouds. It helps to ensure that you use the same settings (font, layout and colours) if you want to compare two documents or wordlists. The two above are for a talk about the genetics of autism and a talk about the social model of disability. The wordclouds can act as an instant summary of the topic. If you are not comparing two topics, then the font, layout and colour could be adjusted to try to convey feelings about the subject, so the image carries even more (subjective) meaning when scanning through a collection of topics.
Wordle can produce instant summaries of books if you have access to the full text source, so you can look at groups of novels, autobiographies and medical textbooks — e.g. the use of person-first or identity-first language, or the use of negative adjectives can be very striking.
If you really want to deconstruct a text, then ANEW (an ’emotion’ wordlist set called Affective Norms for English Words) can be used to grade the positive and negative content of a text. SentiWordNet can be used to locate all the adjectives or adverbs. The two could be combined to grade newspaper articles about a topic for sentiment, to compare different news sources or to examine time trends in reporting. In general, locating over-use of adjectives and adverbs, or excessive sentiment, can be a useful warning when revising text.
Further reading