I have written before about the major topics that appear in newspaper articles that are “about autism”*, with their bias towards articles that mention boys, children, mothering and negative words. Autism is more often written about as a disorder, of a child, in the context of a parent (usually the mother) and as a sufferer, victim or burden. In this post I am looking at how newspapers write about autism itself, the choice of wording and phrasing that surround the words ‘autism’, ‘autistic’ or ‘Asperger’. Trying to visualise the use of words, in large volumes of text, is a very exciting topic and the results here are well worth studying in detail.
My own position on the use of words is to try to accurately reflect the terms that people choose themselves, or in the sources that I am referencing. The images here are convincing evidence that some word choices have a significant effect on positive reporting. In particular, the (identity-first language) adjective ‘autistic’ favours thoughts about personhood and the (person-first language) noun ‘autism’ is associated with negative, dehumanised phrasing. This is consistent with the findings of the survey “Which terms should be used to describe autism? Perspectives from the UK autism community”.
There are some technical notes at the end for anyone interested in the computer methods used to produce the images.
* “about autism” in this context means a newspaper article containing the words ‘autism’, ‘autistic’ or ‘asperger(‘s)’. The images here are based on almost 9,000 articles in the Daily Mail, Irish Examiner and Irish Times between 1995 and 2015.
As with the word frequency analysis, the ideal outcome should not be biased by any preconceptions or choices made by the analyst. Summarising large volumes (5.6 million words) of text is a complex problem. A popular method at the moment is counting ‘positive’ and ‘negative’ sentiments, or specific kinds of ’emotion’ in text to create an average sentiment – for instance the public mood about an airline brand name, as expressed on Twitter.
The method used here is purely word frequency-based. Taking every sentence containing the word of interest, the frequencies of every word and every word-pair are counted. “The cat sat on the mat” would give word frequencies of the:2, cat:1, sat:1, etc., and the word-pair frequencies the->cat:1, sat->on:1, on->the:1, etc. As you can imagine, an image with every word and every pair would be both extremely large and extremely confusing. The images here display only the 70 most frequent word-pairs – the value 70 is an arbitrary compromise between readability and quantity, because the text is too small with many words and connections. For instance, in the Irish Examiner from 1995-2015, the word pair “with autism” appeared 512 times, “children with” 301 times, “autism and” 201 times, etc. There are usually far fewer than 140 individual words because the most frequent word pairs re-use the same words.
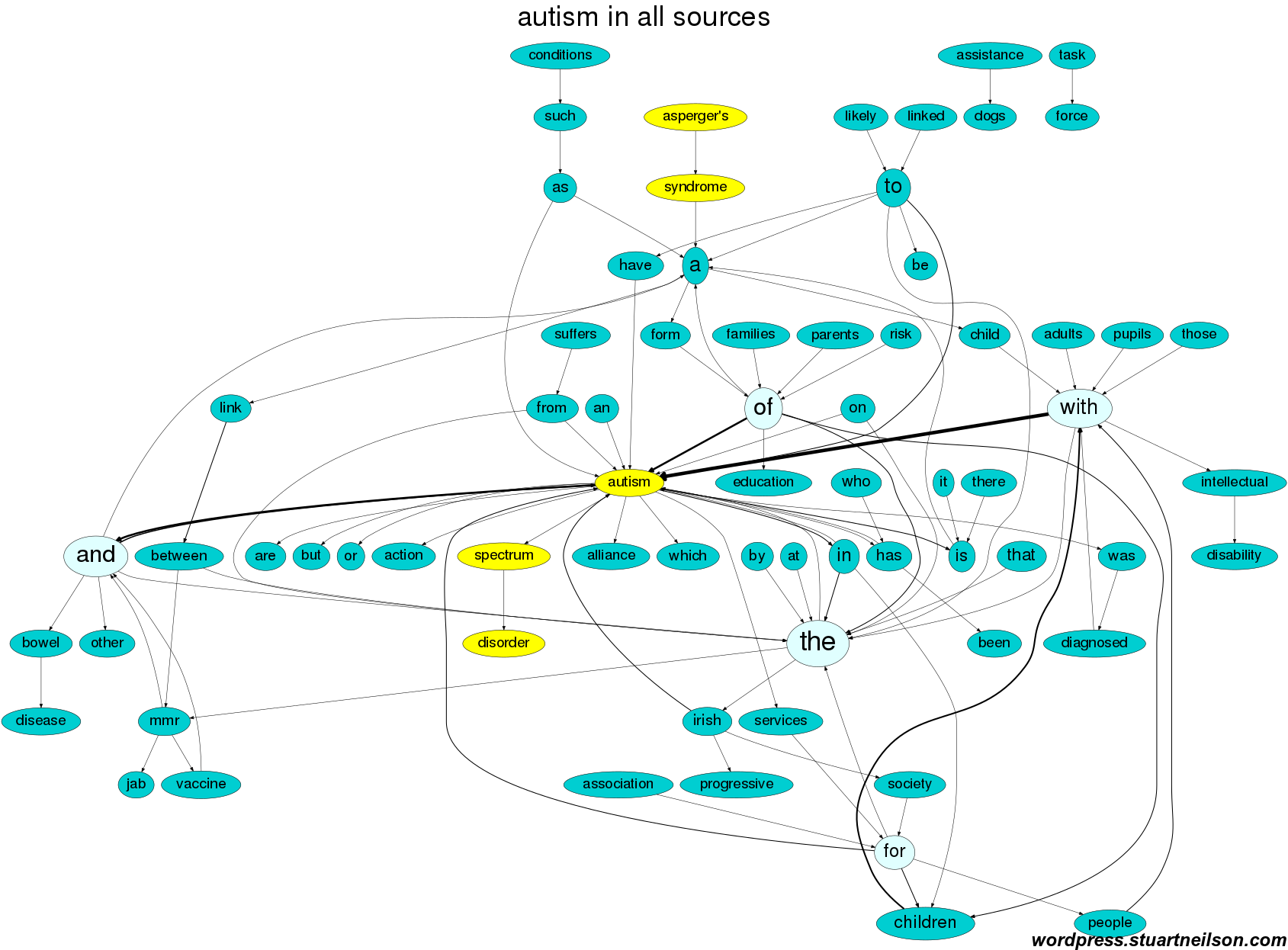
When these words are spread out and connected to show the frequent word pairs, they tend to connect into a network that looks like a syntax diagram and following the arrows displays longer phrases. In the diagram above, you can trace “a child with autism”, “pupils with intellectual disability” and so on. The images here are a 3×3 comparison of the use of the three terms “Asperger(‘s) (symdrome)”, “autism” and “autistic” in the three sources The Daily Mail, The Irish Examiner and The Irish Times. The number of times these terms appeared were:
| Daily Mail | Irish Examiner | Irish Times | |
| ‘autism’ | 7,307 | 1,743 | 3,806 |
| ‘Asperger(‘s)’ | 2,320 | 105 | 524 |
| ‘autistic’ | 3,850 | 820 | 1,776 |
Autism
These are large images, so click on them to open in a larger window, or download them, to view full-screen or zoom in on any areas of interest. The three sources are laid out with the same network for comparison. The words of interest (‘autism’, ‘spectrum’, ‘disorder’, ‘Asperger’, ‘syndrome’ and ‘autistic’) are highlighted in yellow so it is easy to locate them. ‘Negative’ words (‘suffers’, ‘disorder’ and ‘disease’) are marked in light red. The remaining words are cyan. The font height is proportional to the word frequency, so bigger words appeared more often. Line thickness is proportional to word pair frequency, so thick lines are frequent pairings.
In this first image of ‘autism’ in The Daily Mail, the top 70 connections are shown in cyan, yellow and light red. Words from the top 70 pairs in the other two sources that do not appear in the top 70 in the Daily Mail are greyed out. The phrases around ‘autism’ include “child / children / people / diagnosed with autism”, the related “Asperger’s symdrome”, media issues of “bowel disease” and “MMR jab / vaccine” that were covered in 1995-2015, and “suffers”. The top 70 word pairs from the (UK-based) Daily Mail did not include mention of the “Task Force on Autism”, “assistance dogs”, “pupils / education / services”, “families” or the “(Progressive) Irish Autism Alliance / Association / Society”, which do appear in the top 70 word pairs of the two Irish newspapers:
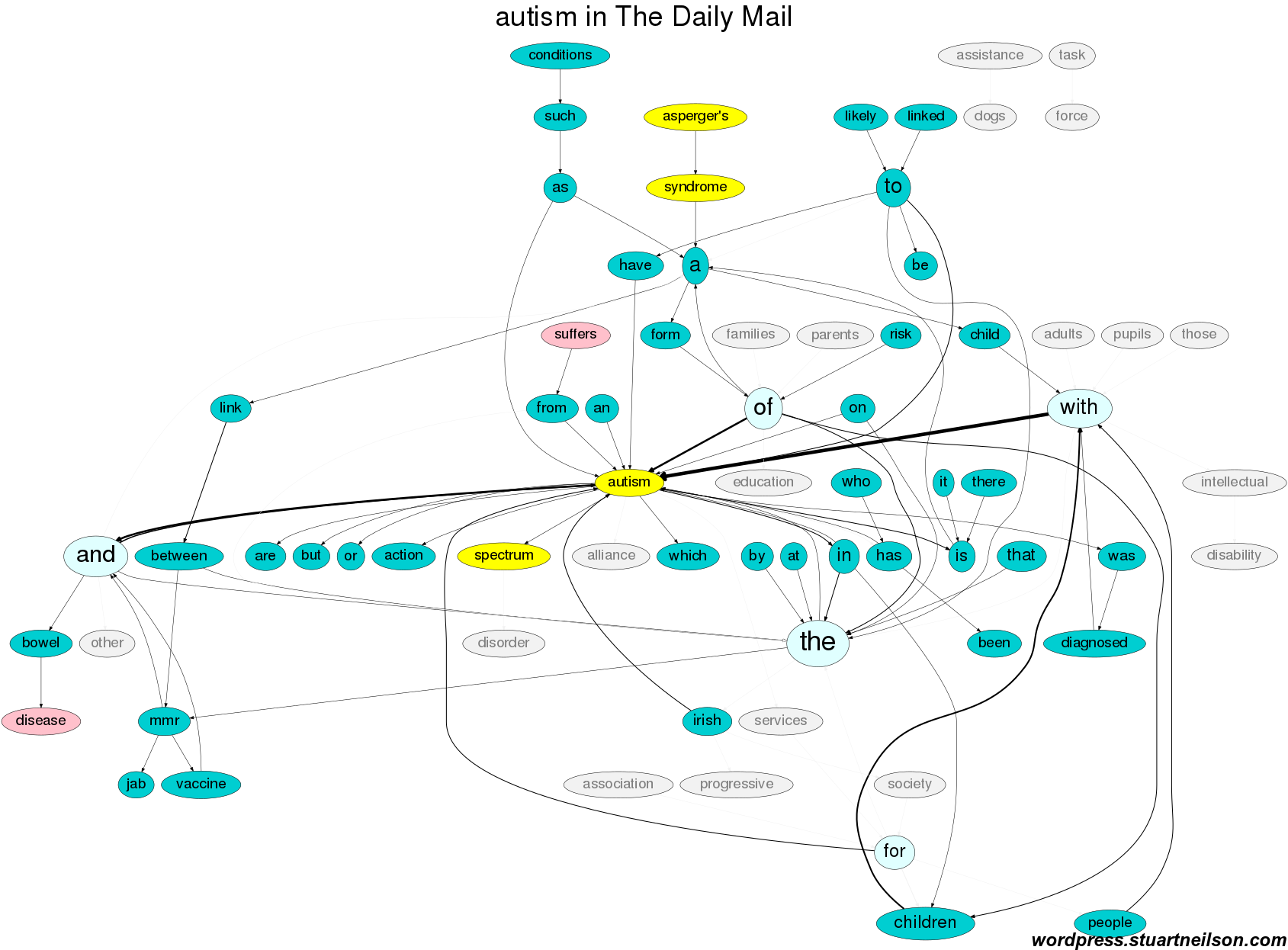
The Irish Examiner, in contrast, does not include “suffers” and does include mention of “assistance dogs” and the Ireland-based autism organisations:

The Irish Times pattern is similar to the Irish Examiner, but does not include mention of “bowel disease” and does include more terms related to government, the “Task Force” and “ecuation / services”:
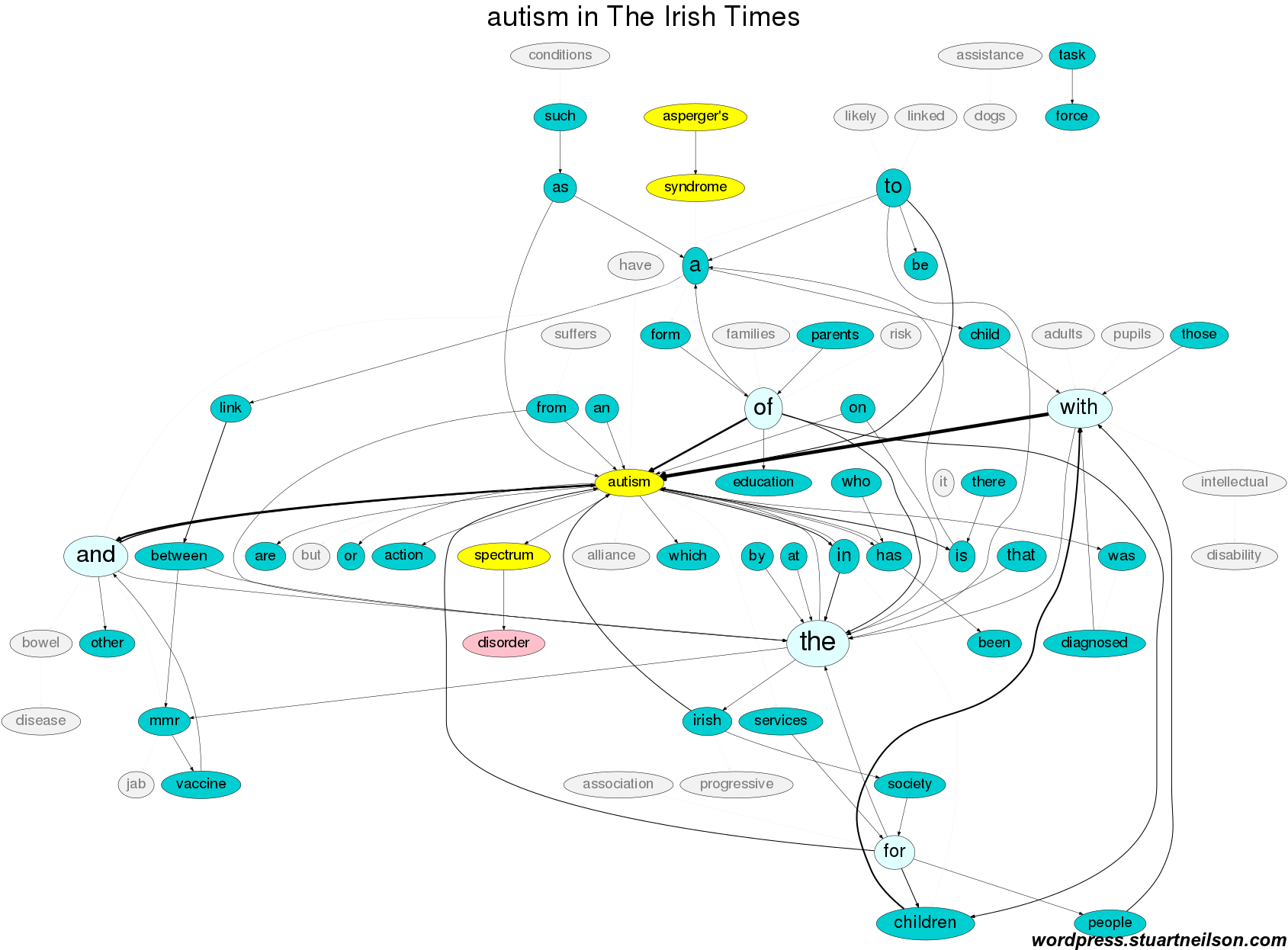 Overall, the tone around ‘autism’ is distant and focused on major media issues rather than the person with ‘autism’.
Overall, the tone around ‘autism’ is distant and focused on major media issues rather than the person with ‘autism’.
Asperger syndrome
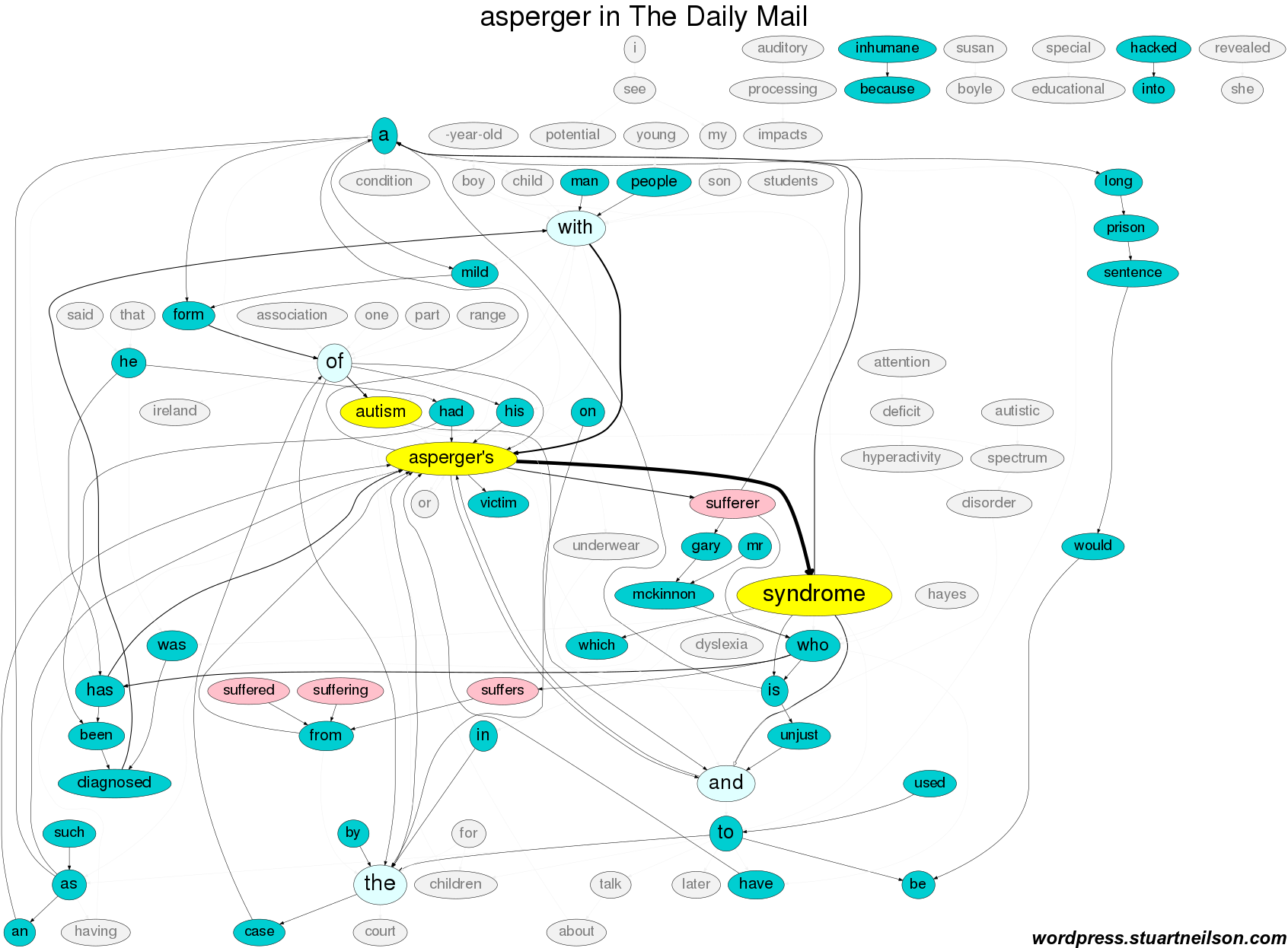
Asperger syndrome is almost always spelled as “Asperger’s Syndrome”, contrary to style guidance which state that “the nonpossessive form should be used uniformly worldwide.”
Counter-intuitively, Asperger syndrome is more often associated (in newspaper text) with suffering and disorder. A typical use in the Daily Mail is “Asperger’s sufferers may be highly intelligent and can hold articulate conversations”, where ‘sufferer’ is the stand-in subject of the sentence, rather than “person with Asperger syndrome”. The Daily Mail demonstrates this burden of (textual) suffering and frequent de-personalised Asperger syndrome existing, disembodied, as a subject of the discussion. The UK media stories around the “unjust / inhumane” treatment of Gary Mackinnon also feature, where he was threatened with extradition to the US and a “long prison sentence” after he “hacked into” various computer systems:
The Irish Examiner has a lower textual burden of suffering and includes the Britain’s Got Talent winner Susan Boyle and more contextual phrases as “a condition”, and “(mild) autistic spectrum disorder”, associated with “atention deficit” and “dyslexia” in “children / boy”, and “I see potential”:
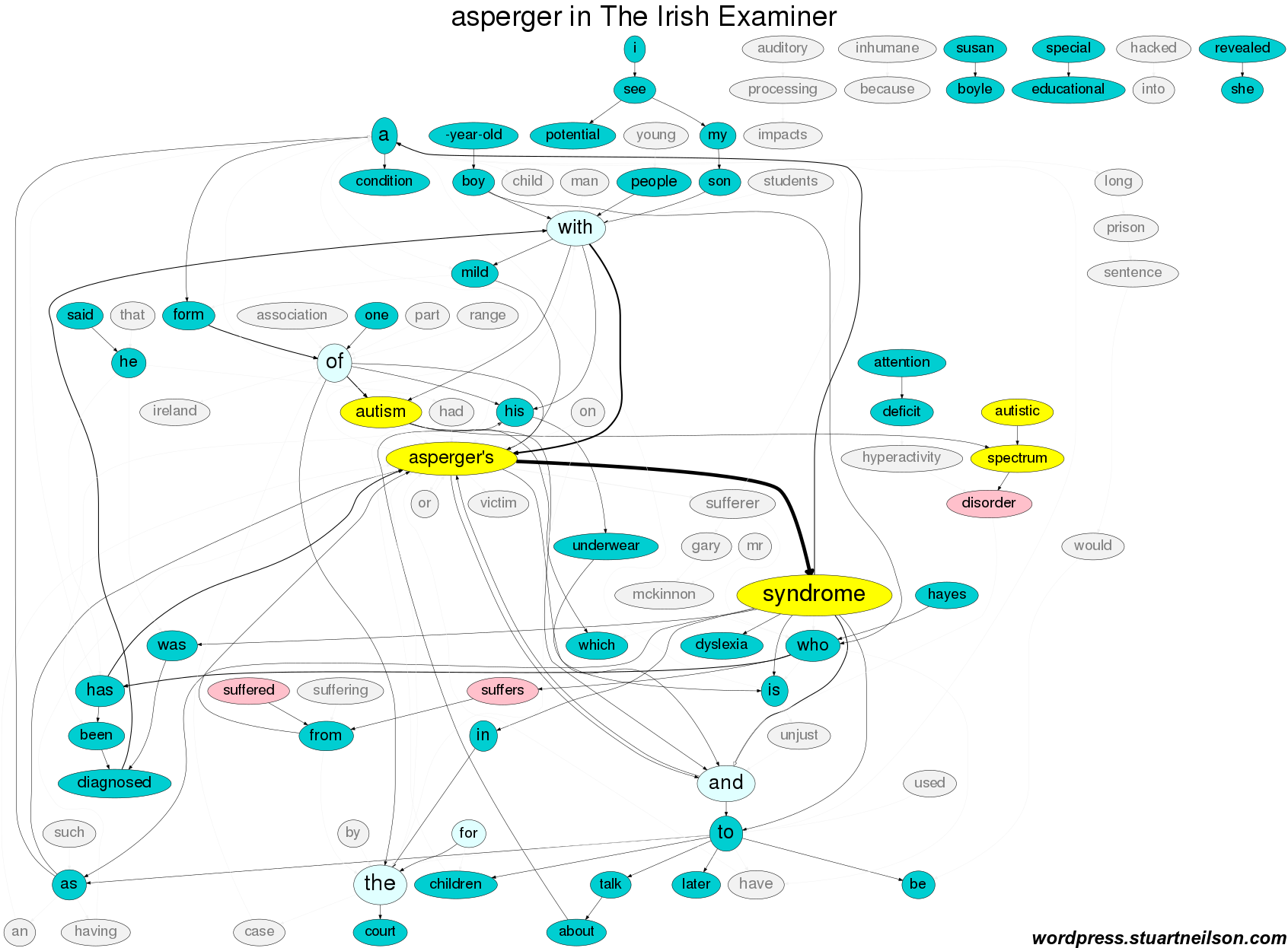
The Irish Times adopts a more sober tone, without mention of TV celebrity, and a similar level of textual suffering as The Irish Examiner:
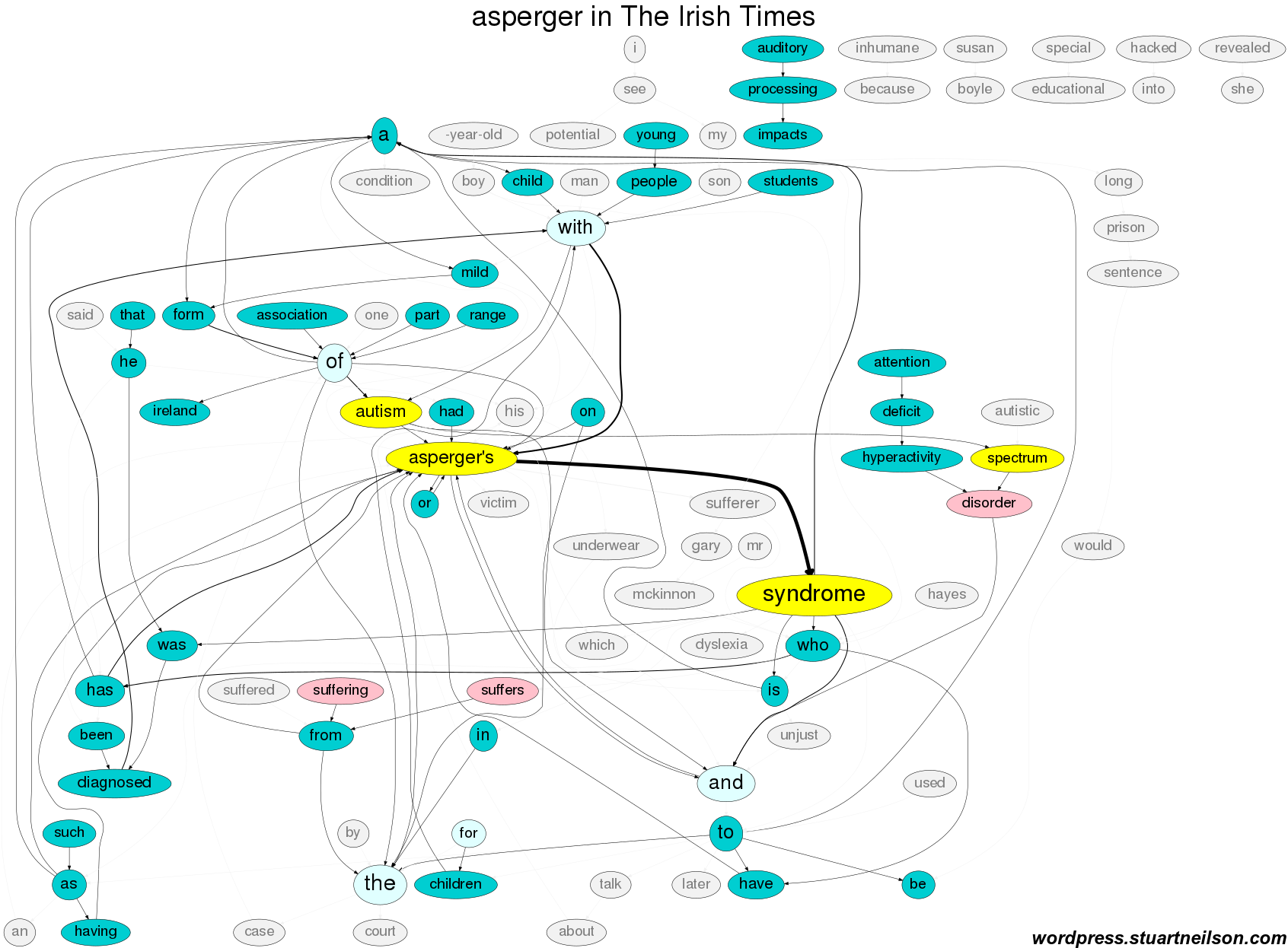
Again, as with the noun ‘autism’, ‘Asperger syndrome’ can be used as the subject of a sentence and the subject of discussion, without any need to refer to the person. The person is frequently defined by the stand-in noun ‘sufferer’, even when the surrounding text includes no reference to any suffering. A flagrant example of anti-suffering is “[Former Barcelona striker Romario claimed that the former forward Lionel] Messi suffers from Asperger’s Syndrome, ‘a mild form of Autism’ that allows him to concentrate and focus more than most people … Messi’s affliction has shown the same traits seen in Albert Einstein and Isaac Newton, and have all been positive in a footballing sense and has brought a lot of joy to the fans.” (Inside Spanish Football).
Autistic
So what happens when the term is an adjective, ‘autistic’, rather than the nouns ‘autism’ or ‘Asperger syndrome’? Autistic people are not defined by suffering. Autistic people are included as “autistic people / man / son / daughter / children” in relation to “school / (state) services / high court” and their “mother / parents”. Gary Mackinnon is mentioned and Mary Carolan is the most frequent Irish Times (Higher Courts) correspondent. The Daily Mail mentions Gary Mackinnon and omits Kathy Sinnot’s “autistic son Jamie”, “education / school / services”:
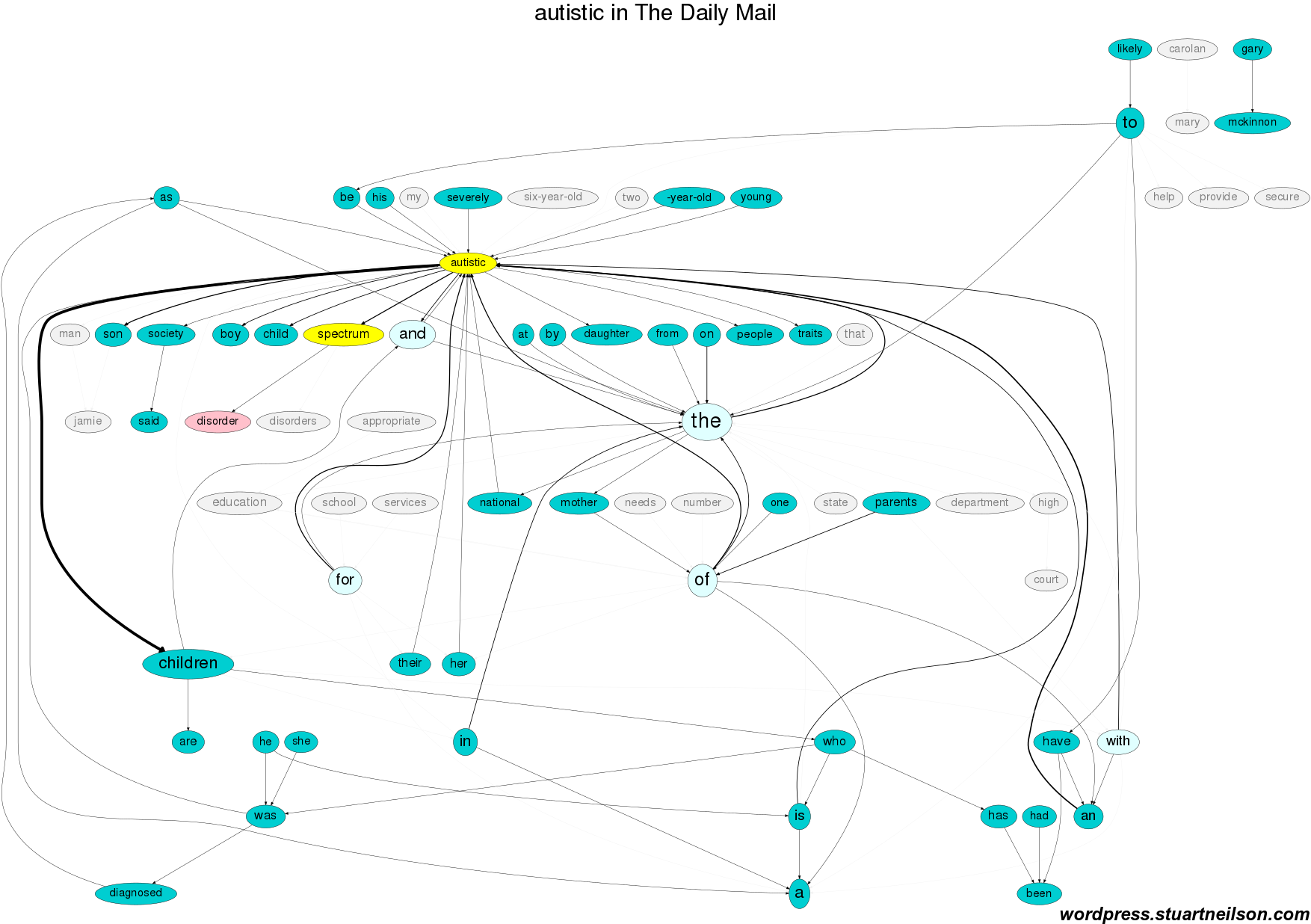
The Irish Examiner is similar, with mention of “education / school”, the “number of autistic people” and without Gary Mackinnon in the top 70 word pairs:
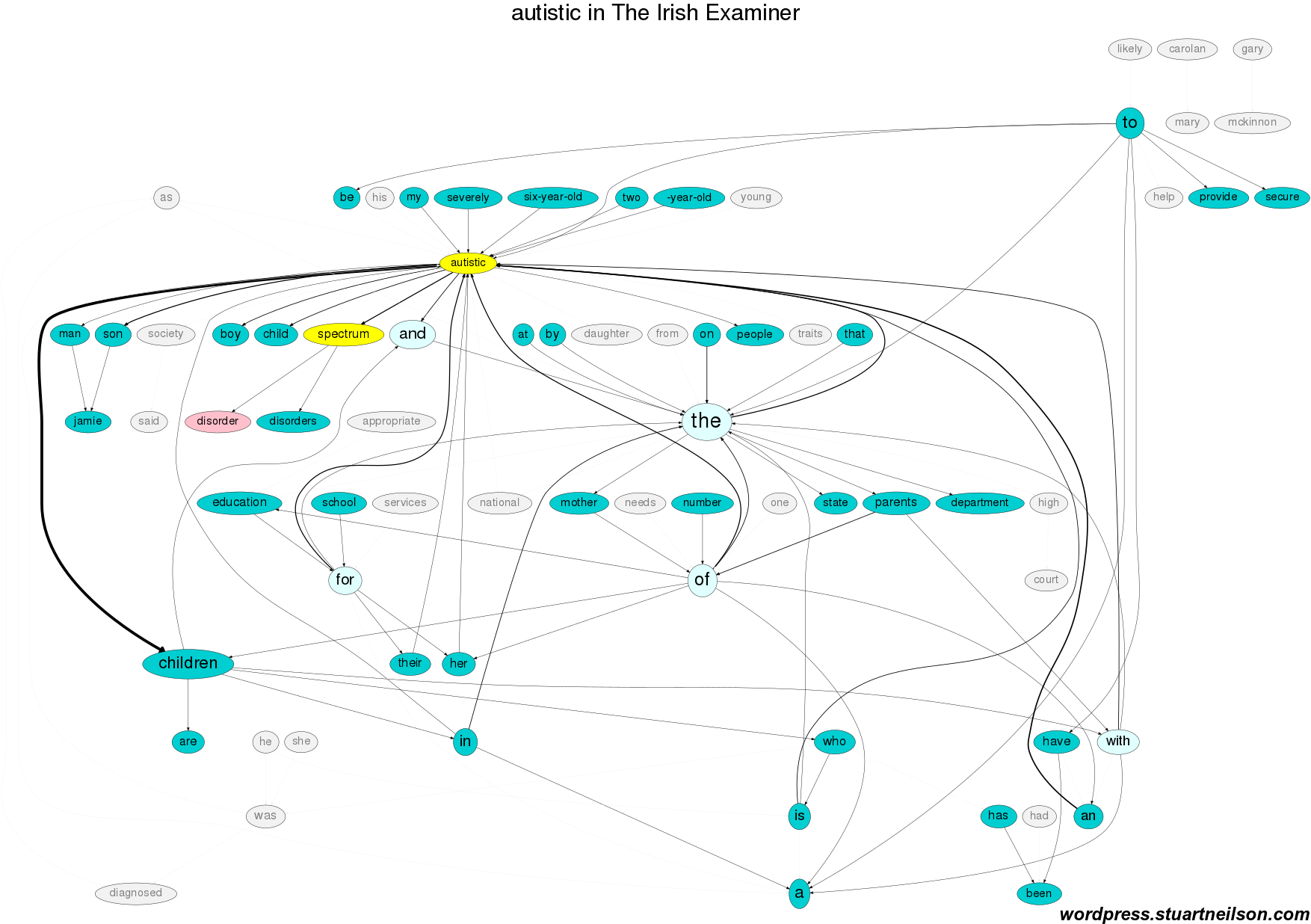
The Irish Times is broadly similar, with the addition of Higher Courts correspondent Mary Carolan and more attention to “appropriate education / services / needs”:
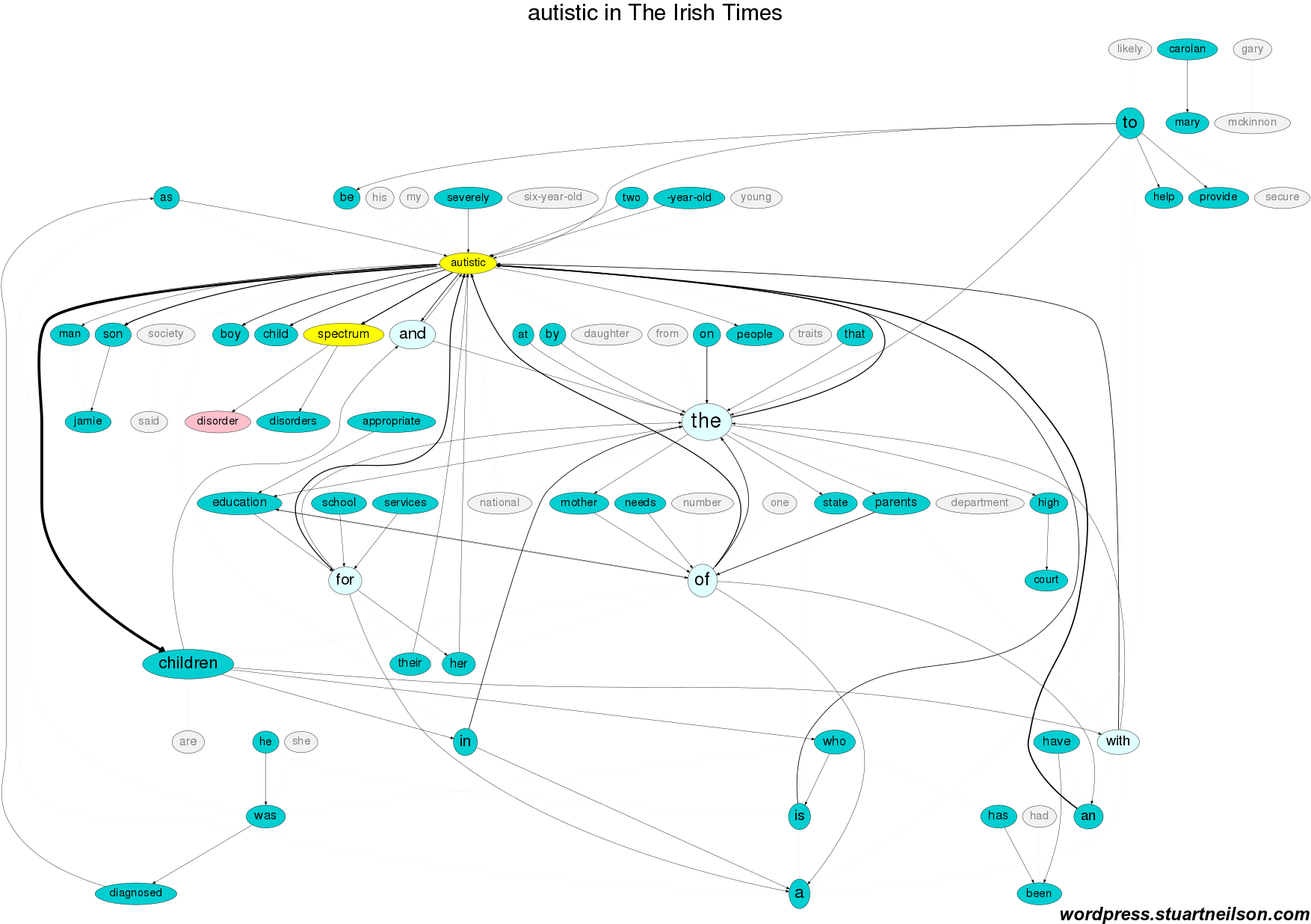
The use of an adjective, ‘autistic’, obliges the writer to follow with an appropriate noun. It is (thankfully) rare to see the “an autistic” or “the autistic”, in the way that “the deaf” or “the blind” are described as de-personalised groups – a mis-use that should be resisted if it ever does appear. Inappropriate references to ‘suffering’, where none is apparent or relevant, are rarer and other attributes take its place.
Autism, as a hostage of journalistic curiosity, plainly benefits from humanising and naming the subject. Frequent references to the person, their attributes, their relationships and their needs oblige a more positive tone that is apparent in all three of these images.
Conclusion
I am ambivalent about the choice of person-first and identity-first language, using whichever reflects the source I am using. This analysis convinces me that there is a real opportunity to promote positive representations of autistic people by recommending the use of identity-first language at all times, which means ‘autistic’ in preference to any other term, including ‘Asperger’ terms, especially in media reporting.
There are good guidelines for media representation in the conclusions to my earlier post on Autism in print news, although I would now reword my final question as “is the autistic person with autism interviewed?” instead of “is the person with autism interviewed?”, leaving less room to discuss a disembodied ‘autism’.
Methods
Anyone interested in applying similar techniques or understanding how these images are produced can read on. I have used only free and open-source software, available to anyone, although some coding might be necessary.
Most of the pre-processing is command line text manipulation, to transform all text to lower case (so ‘Autism’, ‘autism’ and ‘AUTISM’ are all counted as the same word ‘autism’), remove all linefeeds, split the text with linefeeds at the end of sentences (full stop, question mark or exclamation mark) and delete all other punctuation except possessive apostrophes. The Linux commands tr and sed do this very effectively.
A count of the frequency of each unique word and word pair are counted, but only for sentences (now a string of text bounded by a linefeed) containing the target word (selected with grep). The Linux command uniq -c produces frequency lists of words and word pairs. These two lists are ‘nodes’ representing the unique words and ‘edges’ representing word pairs within sentences containing the target word. The text of the sentences containing the target word is now represented by two lists. The first lists all the unique words, the number of times they occur and their rank:
"autism" [wcount=3141,wrank=0]; "the" [wcount=1081,wrank=1]; "and" [wcount=784,wrank=2];
The second lists all the word pairs in the selected sentences, in order from the first word to the second, along with the frequency of the word pair and its rank. The direction is important, so “autism” -> “with” also occurs and is listed separately with a count of 7 (and a rank of 313th most frequent pair):
"with" -> "autism" [ecount=512,erank=1]; "children" -> "with" [ecount=301,erank=2]; "autism" -> "and" [ecount=201,erank=3];
Heading these two lists with “digraph mywords {” and tailing it with “}” creates valid input for the suite of Graphviz tools. The dot tool will produce a PNG image simply with dot -Tpng -o mywords.png mywords.dot, although it will be slow, messy and contain every word and word pair.
The tool gvpr runs a sophisticated range of commands to select nodes and edges, process attributes and style the graph, nodes and edges. For instance gvpr -c ‘E[$.rank > 70] {delete(root, $);}’ will delete every edge with a rank greater than 70, leaving the most frequent 70 word pairs. Adding ‘N[$.degree==0]{delete(root, $);}’ will then delete every node without connecting edges, leaving only the words that are part of the 70 most frequent pairs. The edges can be thickened with $.penwidth=1+$.count/125 (1 pixel, plus 1 pixel for every 125 words). The node size can be enlarged with $.fontsize=36+$.count/30 (36 point text, with another point increase per 30 occurrences of the word). There is plenty of information about these two commands and the full suite in the Graphviz documentation.
Combining sources
Graphviz lays out nodes and edges in the order they are listed and / or processed and will change the layout dramatically to make the best use of space. To create one layout, combining all three sources, I created a new node and edge list with counts from all three sources. In order to treat the three sources equally, I normalised by dividing the word count by the highest word count, to create a new value of 1,000 for the most frequent word. The combined list then contains an average wordcount and counts for DM, IE and IT (in the Daily Mail, Irish Examiner and Irish Times). These will be zero when the word or word-pair does not occur in the top 70 for that source. The node size and edge thickness are defined by the average (normalised) frequency from all three sources.
The all sources image can be produced directly from this combined list. The Daily Mail image can be generated with gvpr and dot by hiding (invisible=true) or greying out the nodes that do not appear (the count DM is zero) in the top 70 pairs in this source: N[$.DM == “0”] {$.fontcolor = “gray50”; $.fillcolor = “gray95”;} E[$.DM == “0”] {$.color = “gray95”;}. The layout will be identical to the all sources image, i.e. all the nodes and edges will be in the same place and of the same size in both images. Doing tha same for IE == 0 and IT == 0 will generate matching images for the Irish Examiner and Irish Times, with only their 70 most frequent word pairs. Opening these images in a viewer allows you to flip back-and-forth between any pair, seeing how the to sources differ.